Q36: What is the Difference between UVM_ALL_ON and UVM_DEFAULT?
UVM_ALL_ON and UVM_DEFAULT are identical. As per the UVM reference manual:UVM_ALL_ON: Set all operations on (default).
UVM_DEFAULT: Use the default flag settings.
It is recommended to use UVM_DEFAULT instead of UVM_ALL_ON even though they both essentially do the same thing today. At some point in time, the class library may add another "bit-flag" which may not necessarily be the DEFAULT.
If you use UVM_ALL_ON, that would imply that whatever flag it is would be "ON".
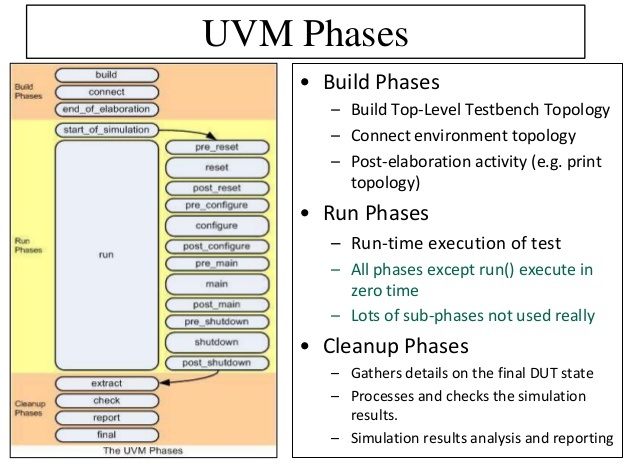
Q37: What drain time in UVM?
The drain time means the access time that you use before ending the simulation. Suppose if we are done with input traffic to the DUT didn't mean that nothing else would happen from that point as the DUT may have required some additional time to complete any transactions that were still being processed. Setting a drain time adds an extra delay from the time that all objections were dropped to the stop of the simulation, making sure that there were no outstanding transactions inside DUT at that point.
You can set the drain time in the base test at the end_of_elobration phase as shown below:
class test_base extends uvm_test; // ... function void end_of_elaboration_phase(uvm_phase phase); uvm_phase main_phase = phase.find_by_name("main", 0); main_phase.phase_done.set_drain_time(this, 10); endfunction // ... endclass
Q38: What is Virtual interface and how Virtual interface is used?
"Virtual interfaces are class data member handles that point to an interface instance. This allows a dynamic class object to communicate with a Design Under Test (DUT) module instance without using hierarchical references to directly access the DUT module ports or internal signals."

Below shown sample code is the easier way to use the virtual interface handles in the UVM environment.
module top;…dut_if dif;…initial beginuvm_config_db#(virtual dut_if)::set(null, "*", "vif", dif);run_test();endendmoduleclass tb_driver extends uvm_driver #(trans1);…virtual dut_if vif;…function void build_phase(uvm_phase phase);super.build_phase(phase);// Get the virtual interface handle that was stored in the// uvm_config_db and assign it to the local vif field.if (!uvm_config_db#(virtual dut_if)::get(this, "", "vif", vif))`uvm_fatal("NOVIF", {"virtual interface must be set for: ",get_full_name(), ".vif"});endfunction…endclass
As shown first the actual interface or physical interface handle, dif, is stored into the uvm_config_db at string location "vif" using the set() command just before the run_test() call in the top level module.
Then it shows the use of the get() function of the uvm_config_db to retrieve the virtual interface handle from the same "vif" location and assign it to the local vif virtual interface handle in the driver class (the same code will be used inside of the monitor class as well).
Q39: How to add a user-defined phase in UVM?
If needed a user can create user-defined phases in the UVM environment. However, this may impact the re-usability of the component. To define a custom phase user need to extend the appropriate base class for phase-type. Following are the available base classes.
class my_phase extends uvm_task_phase;
class my_phase extends uvm_topdown_phase;
class my_phase extends uvm_bottomup_phase;
You can refer to the UVM PHASE IMPLEMENTATION EXAMPLE for complete user-defined phase understanding.
Q40: How interface is passed to components in UVM?
The passing of interface is done using the virtual interface to the component is done using set() and get() methods. consider the below example:
Consider we have defined 2 interfaces as
apb_if intf0(.pclk(clk));
apb_if intf1(.pckl(clk));
Setting the interface:
initial begin
//put in the database the interface used by APB agent agent0
uvm_config_db#(virtual apb_if)::set(null, "uvm_test_top.env.agent0*", "VIRTUAL_INTERFACE", intf0);
//put in the database the interface used by APB agent agent1
uvm_config_db#(virtual apb_if)::set(null, "uvm_test_top.env.agent1*", "VIRTUAL_INTERFACE", intf1);
end
Getting the interface:
class cfs_apb_agent extends uvm_component;
//pointer to the interface
virtual cfs_apb_if vif;
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(uvm_config_db::#(virtual apb_if)::get(this, "", "VIRTUAL_INTERFACE", vif) == 0) begin
`uvm_fatal("ISSUE", "Could not get from the database the virtual interface for the APB agent")
end
endfunction
endclass