Q16: Is uvm is independent of systemverilog ?
Ans: UVM is a methodology based on SystemVerilog language and is not a language on its own. It is a standardized methodology that defines several best practices in verification to enable efficiency in terms of reuse and is also currently part of IEEE 1800.2 working group.
Q17: What are the benefits of using UVM?
Ans: Some of the benefits of using UVM are :
Below is a simple example
Ans: UVM is a methodology based on SystemVerilog language and is not a language on its own. It is a standardized methodology that defines several best practices in verification to enable efficiency in terms of reuse and is also currently part of IEEE 1800.2 working group.
Q17: What are the benefits of using UVM?
Ans: Some of the benefits of using UVM are :
- Modularity and Reusability – The methodology is designed as modular components (Driver, Sequencer, Agents , env etc) which enables reusing components across unit level to multi-unit or chip level verification as well as across projects.
- Separating Tests from Testbenches – Tests in terms of stimulus/sequencers are kept separate from the actual testbench hierarchy and hence there can be reuse of stimulus across different units or across projects
- Simulator independent – The base class library and the methodology is supported by all simulators and hence there is no dependence on any specific simulator
- Better control on Stimulus generation – Sequence methodology gives good control on stimulus generation. There are several ways in which sequences can be developed which includes randomization, layered sequences, virtual sequences etc which provides a good control and rich stimulus generation capability.
- Easy configuration – Config mechanisms simplify configuration of objects with deep hierarchy. The configuration mechanism helps in easily configuring different testbench components based on which verification environment uses it and without worrying about how deep any component is in testbench hierarchy
- Factory mechanism – Factory mechanisms simplifies modification of components easily. Creating each components using factory enables them to be overridden in different tests or environments without changing underlying code base.
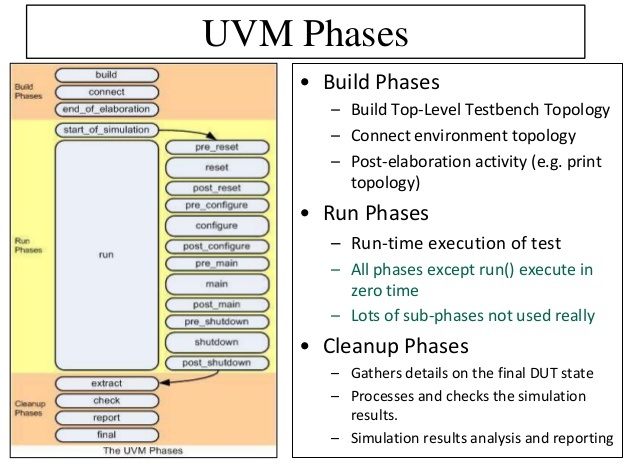
Q18: Can we have user defined phase in UVM?
Ans: In addition to the predefined phases available in uvm , the
user has the option to add his own phase to a component. This is typically done
by extending the uvm_phase class the constructor needs to call super.new which
has three arguments
- Name of the phase task or function
- Top down or bottom up phase
- Task or function
The call_task or
call_func and get_type_name need to be implemented to complete the addition of
new phase.
Example
class custom_phase extends uvm_phase;
function new();
super.new(“custom”,1,1);
endfunction
task call_task ( uvm_component parent);
my_comp_type
comp;
if (
$cast(comp,parent) )
comp.custom_phase();
endtask
virtual function
string get_type_name();
return “custom”;
endfunction
endclass
Q19: What is uvm RAL model ? why it is required ?
Ans: In a verification context, a register model (or register abstraction
layer) is a set of classes that model the memory mapped behavior of registers
and memories in the DUT in order to facilitate stimulus generation and
functional checking (and optionally some aspects of functional coverage). The UVM
provides a set of base classes that can be extended to implement comprehensive
register modeling capabilities.
Q20: What is the difference between new() and create?
Ans: We all know about new() method that is use to allocate
memory to an object instance. In UVM (and OVM), the create() method causes an
object instance to be created from the factory. This allows you to use factory
overrides to replace the desired object with an object of a different type without having to recode.
<< PREVIOUS NEXT >>
<< PREVIOUS NEXT >>